

Perbezaan antara Hadoop dan SQL
- 2761
- 577
- David Collier
Istilah 'Big Data' adalah salah satu kata kunci paling hangat dalam era digital hari ini. Setiap syarikat mulai dari permulaan kecil ke perusahaan besar mempunyai wang untuk data besar. Tiba-tiba kita melihat penumpuan trend penting yang secara asasnya mengubah industri dan terdapat letupan data kerana peningkatan bilangan peranti yang berkaitan dengan internet. Data Besar adalah tepat di mana kerangka sumber terbuka Hadoop datang ke gambar. Hadoop menyediakan rangka kerja untuk menyimpan dan mengambil sejumlah besar data untuk pemprosesan dan tujuan analisis. Tetapi bagaimana Hadoop berbeza daripada sistem pengurusan pangkalan data lain seperti SQL Server? Kami menyerlahkan beberapa perbezaan utama antara SQL dan Hadoop.
Apa itu Hadoop?
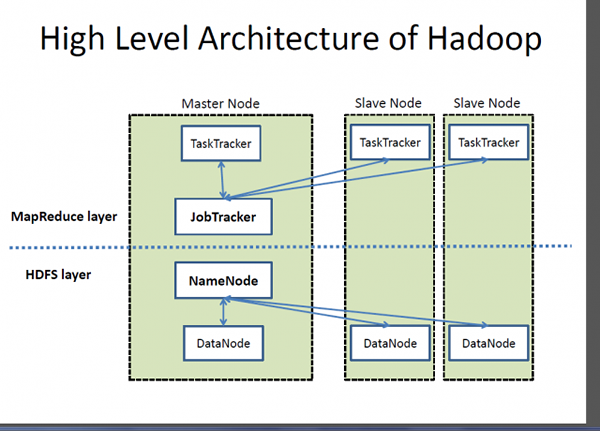
Hadoop adalah rangka kerja pemprosesan yang diedarkan sumber terbuka yang direka untuk memenuhi keperluan syarikat web untuk mengindeks dan memproses jumlah data yang besar, dengan peningkatan peningkatan peranti yang dibolehkan Internet dan evolusi besar seterusnya yang disebut media sosial. Google memberikan inspirasi untuk pembangunan yang dikenali sebagai Hadoop. Ia menyediakan rangka kerja yang membolehkan pemprosesan jumlah data besar -besaran untuk menyediakan akses mudah dan memuatkan data secara dinamik.
Apa itu SQL?
SQL telah menjadi alat di mana -mana untuk mengakses dan memanipulasi data dalam pangkalan data. Pelayan SQ tidak lagi sistem pengurusan pangkalan data biasa yang digunakan oleh pemaju dan pentadbir pangkalan data dan penganalisis. Ini adalah ekosistem yang besar alat dan perkhidmatan perbezaan yang berfungsi bersama untuk menyediakan tugas pengurusan platform data yang sangat kompleks. Ia adalah bahasa de facto untuk sistem sokongan transaksional dan keputusan dan alat perisikan perniagaan untuk mengakses pertanyaan iklan pelbagai sumber data. Malah, pelayan SQL mengendalikan menguatkuasakan kualiti data dan konsistensi jauh lebih baik daripada Hadoop.
Perbezaan antara Hadoop dan SQL
Alat
- Hadoop adalah projek asas perisian Apache dan rangka kerja perisian pemprosesan yang diedarkan sumber terbuka untuk menyimpan dan memproses kemasukan data yang besar dan menjalankan aplikasi pada kelompok perkakasan komoditi. Hadoop menyediakan rangka kerja yang membolehkan pemprosesan jumlah data besar -besaran untuk menyediakan akses mudah dan memuatkan data secara dinamik. SQL, pendek untuk bahasa pertanyaan berstruktur, sebaliknya, adalah bahasa de facto untuk sistem sokongan transaksional dan keputusan dan alat perisikan perniagaan untuk mengakses dan menanyakan pelbagai data dari sumber yang berbeza. SQL telah menjadi alat di mana -mana untuk mengakses, memanipulasi dan menyimpan data dalam pangkalan data.
Rangka Hadoop vs. SQL
- Di teras ekosistem Hadoop adalah dua komponen utama - sistem fail yang diedarkan Hadoop (HDFS) - sistem fail yang diedarkan, berskala dan mudah alih yang ditulis di Java untuk menyimpan set data yang sangat besar di seluruh kluster komputer; dan pendekatan untuk pemprosesan yang diedarkan berdasarkan Java yang dipanggil MapReduce. SQL Server, sebaliknya, adalah sistem pengurusan pangkalan data relasi dan salah satu platform data yang paling berkuasa di dunia yang digunakan oleh beberapa produk komersial dan dalaman untuk menanyakan, memanipulasi dan menggambarkan pelbagai sumber data.
Jenis data
- Hadoop direka untuk bekerja dengan mana-mana jenis data, sama ada berstruktur, berstruktur atau tidak berstruktur, menjadikannya sangat fleksibel untuk bekerja dengan pemprosesan data besar. SQL, sebaliknya, adalah bahasa pengaturcaraan yang dibuat khusus untuk mengurus dan menanyakan data dalam sistem pengurusan pangkalan data relasi (RDBMS). Ia berdasarkan model entiti-hubungan RDBMS, jadi hanya dapat memproses data berstruktur. SQL tidak boleh digunakan untuk data yang tidak tersusun kerana mereka tidak mematuhi model data tanpa struktur yang mudah dikenal pasti.
Pemprosesan
- HDFS adalah sistem fail yang diedarkan yang direka untuk menyokong pemprosesan batch data makna data dikumpulkan dalam kelompok dan setiap kumpulan dihantar untuk diproses. Kumpulan boleh menjadi apa -apa dari satu hari hingga satu minit. Oleh kerana ia direka untuk pemprosesan batch, ia tidak mempunyai konsep bacaan rawak atau menulis. SQL Server, sebaliknya, sebagai platform pangkalan data tujuan umum, menyokong pemprosesan data masa nyata, yang bermaksud data disiarkan dari pengirim ke penerima sebaik sahaja ia dihasilkan di hujung sumber.
Prestasi Hadoop dan SQL
- Senibina Hadoop kadang -kadang membawa kepada ketidakpadanan impedans antara penyimpanan data dan akses data. Ia mempunyai sekatan atau pengesahan yang lebih sedikit pada data yang disimpannya, dan ia tidak mempunyai keupayaan pengguna akhir yang sama dan ekosistem yang telah dibangunkan oleh SQL. SQL Server, sebaliknya, mengendalikan menguatkuasakan kualiti data dan konsistensi jauh lebih baik daripada Hadoop yang membolehkannya memanfaatkan ekosistem analisis data berasaskan SQL dan alat visualisasi data. Walau bagaimanapun, SQL juga mempunyai beberapa kelemahan yang termasuk skalabiliti untuk mengendalikan sejumlah besar data dan sokongan untuk menyimpan data yang diformat secara longgar.
Hadoop vs. SQL: Carta Perbandingan

Ringkasan Hadoop vs. SQL
Hadoop adalah alat data besar yang paling disukai dan diterima secara meluas untuk bekerja dengan mana -mana jenis data - berstruktur, tidak berstruktur atau berstruktur. Tetapi ketika datang ke RDBMS, SQL mungkin sistem penyimpanan data dan pengurusan data yang paling kuat, memori dan dinamik. Walau bagaimanapun, penyelesaian RDBMS yang ada seperti pelayan SQL hanya untuk menguruskan jumlah data yang ketara, tetapi bukan untuk data tidak berstruktur atau separa berstruktur dengan atribut berubah-ubah. Seperti banyak platform, Hadoop dan SQL Server kedua -duanya mempunyai bahagian kekuatan dan kelemahannya. Gunakan kedua -dua mereka bersama -sama dan anda boleh memanfaatkan kekuatan masing -masing sambil mengurangkan kelemahan.
- « Perbezaan antara pengiktirafan pertuturan dan pemprosesan bahasa semula jadi
- Perbezaan antara biosensor dan biochip »