

Perbezaan antara varians sampel & varians penduduk
- 2766
- 554
- Ricardo Koelpin IV
Penjelasan
Dalam statistik, istilah persampelan merujuk kepada pemilihan sebahagian daripada data statistik agregat untuk tujuan mendapatkan maklumat yang relevan mengenai keseluruhannya. Agregat atau keseluruhan maklumat statistik mengenai watak tertentu semua ahli yang dilindungi oleh siasatan dipanggil 'penduduk' atau 'alam semesta'. (Das, n.G., 2010). Bahagian terpilih penduduk yang digunakan untuk mendapatkan ciri -ciri penduduk atau alam semesta disebut sebagai 'sampel'. Penduduk diambil untuk dibuat daripada unit atau ahli individu, dan beberapa unit dimasukkan ke dalam sampel. Jumlah unit penduduk dipanggil saiz populasi, dan sampel itu dipanggil saiz sampel. Populasi dan sampel boleh menjadi terhingga atau tidak terhingga dan juga mereka boleh wujud atau hipotesis.
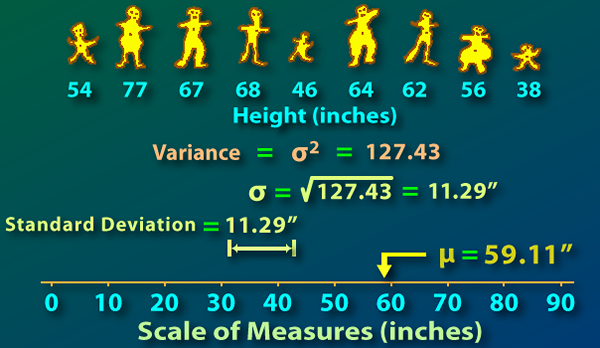
Varians: Varians adalah nilai berangka yang menunjukkan bagaimana angka individu dalam satu set data mengedarkan diri mengenai min. Itulah sejauh mana setiap nombor adalah dari min, dan dengan itu antara satu sama lain. Varians nilai sifar bermaksud semua data adalah sama. Lebih banyak varians, lebih banyak nilai yang tersebar luas, oleh itu antara satu sama lain. Kurang varians, kurang adalah nilai -nilai yang tersebar mengenai min, oleh itu antara satu sama lain, dan varians tidak boleh negatif.
Perbezaan antara varians penduduk dan varians sampel
Perbezaan utama antara varians populasi dan varians sampel berkaitan dengan pengiraan varians. Varians dikira dalam lima langkah. Maksud pertama dikira, maka kita mengira penyimpangan dari min, dan ketiga -tiga penyimpangan itu dikelilingi, keempat penyelewengan kuadrat disimpulkan dan akhirnya jumlah ini dibahagikan dengan bilangan item yang mana varians dikira. Oleh itu varians = σ (xi-x-)/n. Di mana xi = ith. Nombor, x- = min dan n = bilangan item ..
Sekarang, apabila varians dikira dari data populasi, n adalah sama dengan bilangan item. Oleh itu, jika varians dalam tekanan darah semua 1000 orang akan dikira dari data mengenai tekanan darah semua 1000 orang, maka n = 1000. Walau bagaimanapun, apabila varians dikira dari data sampel 1 akan ditolak dari n sebelum membahagikan jumlah penyimpangan kuadrat. Oleh itu, dalam contoh di atas jika data sampel mempunyai 100 item, penyebutnya akan menjadi 100 - 1 = 99.
Oleh kerana itu, nilai varians yang dikira dari data sampel lebih tinggi daripada nilai yang dapat dijumpai dengan menggunakan data populasi. Logik melakukan itu adalah untuk mengimbangi kekurangan maklumat mengenai data penduduk. Tidak mustahil untuk mengetahui varians ketinggian manusia, kerana kekurangan maklumat mutlak kita tentang ketinggian semua manusia yang hidup, bukan untuk bercakap tentang masa depan. Walaupun kita mengambil satu contoh yang sederhana, seperti data populasi pada ketinggian semua lelaki yang hidup di dalam kita, mungkin secara fizikal, tetapi kos dan masa yang terlibat dalam hal ini akan mengalahkan tujuan pengiraannya. Inilah sebab data sampel diambil untuk kebanyakan tujuan statistik, dan ini disertakan dengan kekurangan maklumat mengenai majoriti data. Untuk mengimbangi ini, nilai varians dan sisihan piawai, yang merupakan akar varians yang lebih tinggi adalah lebih tinggi sekiranya data sampel daripada varians dari data populasi.
Ini berfungsi sebagai perisai automatik untuk penganalisis dan pembuat keputusan. Logik memohon keputusan mengenai belanjawan modal, kewangan peribadi dan perniagaan, pembinaan, pengurusan lalu lintas, dan banyak bidang yang berkenaan. Ini membantu pemegang saham berada di tempat yang selamat semasa mengambil keputusan atau untuk kesimpulan lain.
Ringkasan: Varians populasi merujuk kepada nilai varians yang dikira dari data populasi, dan varians sampel adalah varians yang dikira dari data sampel. Oleh kerana nilai penyebut ini dalam formula untuk varians dalam kes data sampel adalah 'n-1', dan ia adalah 'n' untuk data penduduk. Akibatnya kedua -dua varians dan sisihan piawai yang diperolehi daripada data sampel adalah lebih daripada yang dijumpai dari data penduduk.