

Perbezaan antara data besar dan hadoop

- 5075
- 518
- Lionel Klocko
Hubungan antara Big Data dan Hadoop adalah salah satu topik penting yang menarik di kalangan pemula. Dan perbezaan antara kedua -dua konsep yang berkaitan ini agak menarik. Data Besar adalah aset yang berharga yang tanpa pengendali tidak menggunakannya. Oleh itu, Hadoop adalah pengendali yang membawa nilai terbaik dari aset. Mari kita lihat dengan dekat kedua -duanya diikuti oleh perbezaan antara kedua -duanya.
Apa itu data besar?
Di dunia digital hari ini, kita dikelilingi oleh banyak data. Ia akan cukup untuk mengatakan bahawa data ada di mana -mana. Evolusi pesat Internet dan Internet Peranti (IoT), dan penggunaan berterusan media elektronik telah membawa kepada kelahiran e-dagang dan media sosial. Akibatnya, jumlah data yang besar telah dihasilkan dan sebenarnya, masih menjana setiap hari. Walau bagaimanapun, data tidak berguna melainkan jika anda mempunyai kemahiran yang diperlukan untuk menganalisisnya. Data dalam bentuk semasa adalah data mentah, yang kebanyakannya adalah kandungan yang dihasilkan oleh pengguna, yang perlu dianalisis dan disimpan. Data dihasilkan dari pelbagai sumber dari media sosial ke sistem tertanam/deria, log mesin, laman e-dagang, dll. Memproses jumlah data yang gila adalah mencabar. Data Besar adalah istilah payung yang merujuk kepada banyak cara bagaimana data dapat diuruskan secara sistematik dan diproses secara besar -besaran. Data besar merujuk kepada set data yang besar dan kompleks yang terlalu rumit untuk dianalisis dengan aplikasi pemprosesan data tradisional.
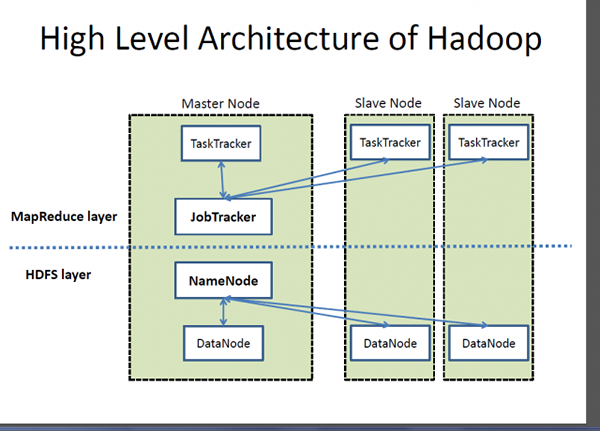
Apa itu Hadoop?
Sekiranya Big Data adalah aset yang sangat berharga, Hadoop adalah program atau alat untuk mengeluarkan nilai terbaik dari aset tersebut. Hadoop adalah program utiliti perisian sumber terbuka yang dibangunkan untuk menangani masalah menyimpan dan memproses set data yang besar dan kompleks. Apache Hadoop mungkin salah satu kerangka perisian yang paling popular dan digunakan secara meluas yang digunakan untuk menyimpan dan memproses data besar. Ini adalah model pengaturcaraan yang mudah yang membolehkan anda menulis dan memeriksa sistem yang diedarkan dengan mudah dan pengagihan pengetahuan automatik dan ekonomi di seluruh komoditi pelayan berkumpul. Apa yang menjadikan Hadoop tersendiri adalah keupayaannya untuk meningkatkan dari satu pelayan ke beribu -ribu mesin pelayan komoditi. Ringkasnya, Apache Hadoop adalah rangka kerja perisian de facto untuk menyimpan dan memproses sejumlah besar data, yang sering disebut sebagai data besar. Dua komponen utama ekosistem Hadoop adalah Sistem Fail Teragih Hadoop (HDFS) dan model pengaturcaraan MapReduce.
Perbezaan antara data besar dan hadoop
Asas
- Data Besar dan Hadoop adalah dua istilah yang paling biasa berkait rapat antara satu sama lain dengan cara yang tanpa Hadoop, data besar tidak akan mempunyai makna atau nilai. Fikirkan data besar sebagai aset nilai yang mendalam, tetapi untuk membawa nilai dari aset itu, anda memerlukan jalan. Oleh itu, Apache Hadoop adalah program utiliti yang direka untuk membawa nilai terbaik daripada data besar. Data besar merujuk kepada set data yang besar dan kompleks yang terlalu rumit untuk dianalisis dengan aplikasi pemprosesan data tradisional. Apache Hadoop adalah rangka kerja perisian yang digunakan untuk mengendalikan masalah menyimpan dan memproses set data yang besar dan kompleks.
Konsep
- Data dalam bentuk mentahnya tidak berguna dan sangat sukar untuk bekerja dengan melainkan jika anda menukar entiti mentah ini yang disebut data ke dalam maklumat. Kami dikelilingi oleh banyak banyak data yang kita lihat dan digunakan dalam era digital ini. Sebagai contoh, kami mempunyai banyak kandungan di laman media sosial dan aplikasi seperti Twitter, Instagram, YouTube, dll. Oleh itu, Big Data merujuk kepada jumlah besar data berstruktur dan tidak berstruktur dan maklumat yang kita dapat keluar dari data ini, seperti corak, trend atau apa sahaja yang akan membantu menjadikan data ini lebih mudah untuk bekerja dengan. Hadoop adalah rangka kerja perisian yang diedarkan yang mengendalikan penyimpanan dan pemprosesan set data yang besar di seluruh komoditi pelayan berkumpul.
Matlamat
- Data dalam bentuk semasa adalah data mentah, yang kebanyakannya adalah kandungan yang dihasilkan oleh pengguna, yang perlu dianalisis dan disimpan. Set data berkembang pada kadar eksponen dan mereka semakin tidak terkawal. Oleh itu, kita perlu cara mengendalikan semua data berstruktur dan tidak berstruktur ini dan kita memerlukan model pengaturcaraan yang mudah yang akan memberikan penyelesaian yang tepat kepada dunia data besar. Ini memerlukan model pengiraan skala besar yang bertentangan dengan model pengiraan tradisional. Apache Hadoop adalah sistem yang diedarkan yang membolehkan pengiraan diedarkan di beberapa mesin dan bukannya menggunakan mesin tunggal. Ia direka untuk mengedarkan dan memproses sejumlah besar data merentasi nod dalam kelompok.
Data besar vs. Hadoop: Carta Perbandingan
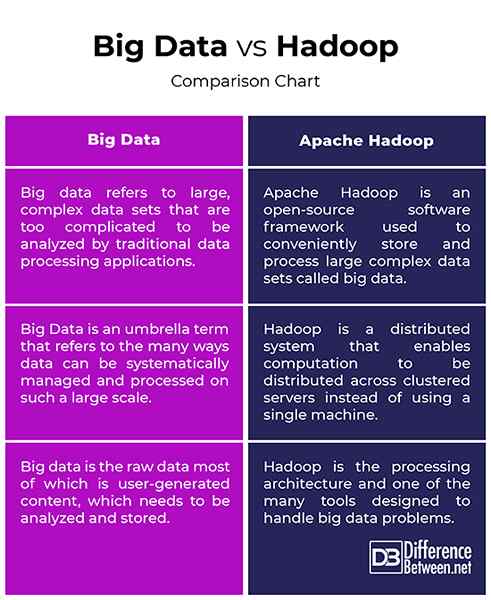
Ringkasan Data Besar vs. Hadoop
Data Besar adalah aset yang sangat berharga yang tidak berguna kecuali kita mencari jalan untuk mengusahakannya. Aplikasi media sosial seperti Twitter, Facebook, Instagram, YouTube, dll. adalah contoh kehidupan sebenar data besar yang menimbulkan beberapa cabaran kepada teknologi yang kita gunakan hari ini. Data yang berkembang pesat dengan kandungan tidak berstruktur ini biasanya dirujuk sebagai data besar. Tetapi, data dalam bentuk mentahnya sangat sukar untuk bekerjasama. Kami memerlukan cara untuk memperoleh, menyimpan, memproses dan menganalisis data ini supaya kami dapat mendapatkan sesuatu yang berguna daripadanya, seperti corak atau trend. Hadoop adalah alat yang membantu menyimpan dan memproses set data kompleks ini yang terlalu besar untuk dikendalikan menggunakan teknik dan alat pengiraan tradisional.