

Perbezaan antara Hadoop dan Spark
- 2476
- 471
- Ricardo Koelpin IV
Salah satu masalah terbesar berkenaan dengan data besar adalah bahawa sejumlah besar masa dibelanjakan untuk menganalisis data yang termasuk mengenal pasti, membersihkan dan mengintegrasikan data. Jumlah data yang besar dan keperluan menganalisis data yang membawa kepada sains data. Tetapi selalunya data tersebar di banyak aplikasi dan sistem perniagaan yang menjadikannya agak sukar untuk dianalisis. Oleh itu, data perlu dihidupkan semula dan diperbaharui untuk memudahkannya menganalisis. Ini memerlukan penyelesaian yang lebih canggih untuk menjadikan maklumat lebih mudah diakses oleh pengguna. Apache Hadoop adalah salah satu penyelesaian yang digunakan untuk menyimpan dan memproses data besar, bersama dengan pelbagai alat data besar lain termasuk Apache Spark. Tetapi yang mana rangka kerja yang tepat untuk pemprosesan data dan menganalisis - Hadoop atau Spark? Mari kita cari.
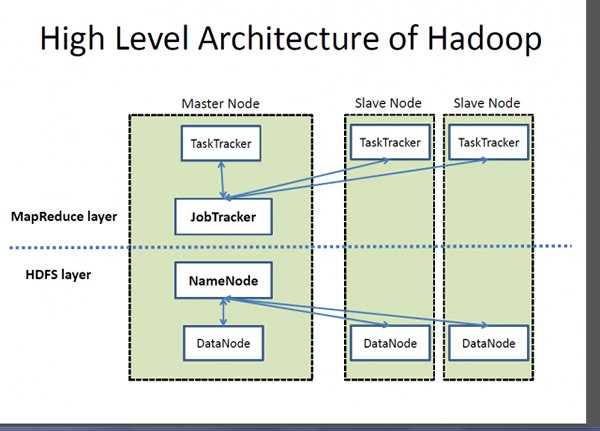
Apache Hadoop
Hadoop adalah tanda dagangan berdaftar Yayasan Perisian Apache dan rangka kerja sumber terbuka yang direka untuk menyimpan dan memproses set data yang sangat besar di seluruh kelompok komputer. Ia mengendalikan data berskala besar dengan kos yang berpatutan dalam masa yang munasabah. Di samping itu, ia juga menyediakan mekanisme untuk meningkatkan prestasi pengiraan pada skala. Hadoop menyediakan rangka kerja pengiraan untuk menyimpan dan memproses data besar menggunakan model pengaturcaraan MapReduce Google. Ia boleh berfungsi dengan pelayan tunggal atau boleh meningkatkan termasuk beribu -ribu mesin komoditi. Walaupun, Hadoop dibangunkan sebagai sebahagian daripada projek sumber terbuka dalam Yayasan Perisian Apache berdasarkan Paradigma MapReduce, hari ini terdapat pelbagai pengagihan untuk Hadoop. Walau bagaimanapun, MapReduce masih merupakan kaedah penting yang digunakan untuk pengagregatan dan pengiraan. Idea asas yang berasaskan MapReduce adalah pemprosesan data selari.

Apache Spark
Apache Spark adalah enjin pengkomputeran kluster sumber terbuka dan satu set perpustakaan untuk pemprosesan data berskala besar pada kluster komputer. Dibina di atas model MapReduce Hadoop, Spark adalah enjin sumber terbuka yang paling aktif untuk membuat analisis data lebih cepat dan menjadikan program berjalan lebih cepat. Ia membolehkan analisis masa nyata dan maju di platform Apache Hadoop. Inti Spark adalah enjin pengkomputeran yang terdiri daripada penjadualan, pengedaran dan pemantauan aplikasi yang terdiri daripada banyak tugas pengkomputeran. Matlamat memandu utama adalah untuk menawarkan platform bersatu untuk menulis aplikasi data besar. Spark pada asalnya dilahirkan di Makmal APM di Universiti Berkeley dan kini ia merupakan salah satu projek sumber terbuka teratas di bawah portfolio Yayasan Perisian Apache. Keupayaan pengkomputeran dalam memori yang tidak dapat ditandingi membolehkan aplikasi analitik berjalan sehingga 100 kali lebih cepat pada Apache Spark daripada teknologi lain yang serupa di pasaran hari ini.
Perbezaan antara Hadoop dan Spark
Rangka Kerja
- Hadoop adalah tanda dagangan berdaftar Yayasan Perisian Apache dan rangka kerja sumber terbuka yang direka untuk menyimpan dan memproses set data yang sangat besar di seluruh kelompok komputer. Pada asasnya, ini adalah enjin pemprosesan data yang mengendalikan data skala yang sangat besar pada kos yang berpatutan dalam masa yang munasabah. Apache Spark adalah enjin pengkomputeran kluster sumber terbuka yang dibina di atas model MapReduce Hadoop untuk pemprosesan data berskala besar dan menganalisis pada kluster komputer. Spark membolehkan analisis masa nyata dan maju di platform Apache Hadoop untuk mempercepat proses pengkomputeran Hadoop.
Prestasi
- Hadoop ditulis di Java sehingga memerlukan menulis kod panjang yang memerlukan lebih banyak masa untuk pelaksanaan program. Pelaksanaan Hadoop MapReduce yang asalnya dibangunkan adalah inovatif tetapi juga agak terhad dan juga tidak begitu fleksibel. Apache Spark, sebaliknya, ditulis dalam bahasa Scala yang ringkas dan elegan untuk menjadikan program berjalan lebih mudah dan lebih cepat. Malah, ia dapat menjalankan aplikasi sehingga 100 kali lebih cepat daripada bukan sahaja Hadoop tetapi juga teknologi serupa yang lain di pasaran.
Kemudahan penggunaan
- Paradigma Hadoop MapReduce adalah inovatif tetapi agak terhad dan tidak fleksibel. Program MapReduce dijalankan dalam kumpulan dan mereka berguna untuk pengagregatan dan mengira secara besar -besaran. Spark, sebaliknya, menyediakan API yang konsisten dan komposis. API Spark juga direka untuk membolehkan prestasi tinggi dengan mengoptimumkan seluruh perpustakaan dan fungsi yang disusun bersama dalam program pengguna. Dan sejak cache percikan kebanyakan data input dalam ingatan, terima kasih kepada RDD (dataset yang diedarkan secara berdaya tahan), ia menghapuskan keperluan untuk memuatkan beberapa kali ke dalam memori dan penyimpanan cakera.
Kos
- Sistem Fail Hadoop (HDFS) adalah cara yang berkesan untuk menyimpan jumlah data yang besar yang berstruktur dan tidak berstruktur di satu tempat untuk analisis mendalam. Kos Hadoop per terabyte jauh lebih rendah daripada kos teknologi pengurusan data lain yang digunakan secara meluas untuk mengekalkan gudang data perusahaan. Spark, sebaliknya, bukanlah pilihan yang lebih baik apabila ia berkaitan dengan kecekapan kos kerana ia memerlukan banyak RAM untuk data cache dalam ingatan, yang meningkatkan kluster, oleh itu kosnya sedikit, berbanding dengan Hadoop.
Hadoop vs. Spark: Carta Perbandingan

Ringkasan Hadoop vs. Percikan
Hadoop bukan sahaja merupakan alternatif yang ideal untuk menyimpan sejumlah besar data berstruktur dan tidak berstruktur dengan cara yang berkesan, ia juga menyediakan mekanisme untuk meningkatkan prestasi pengiraan pada skala. Walaupun, ia pada asalnya dibangunkan sebagai projek Yayasan Perisian Apache Terbuka berdasarkan model MapReduce Google, terdapat pelbagai pengagihan yang berbeza untuk Hadoop hari ini. Apache Spark dibina di atas model MapReduce untuk memperluaskan kecekapannya untuk menggunakan lebih banyak jenis perhitungan termasuk pemprosesan aliran dan pertanyaan interaktif. Spark membolehkan analisis masa nyata dan maju di platform Apache Hadoop untuk mempercepat proses pengkomputeran Hadoop.