

Perbezaan antara HBase dan Hive
- 3991
- 706
- Ms. Armando Hammes
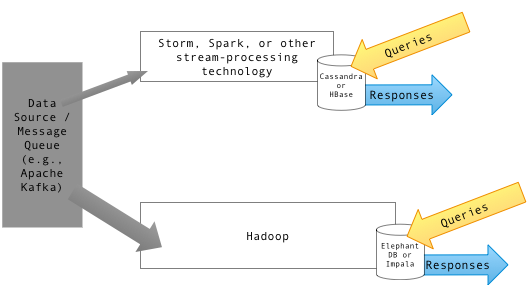
HBase dan Hive adalah struktur gudang data berasaskan Hadoop yang berbeza dengan cara mereka menyimpan dan menanyakan data. Menguruskan dan memproses sejumlah besar data berasaskan web menjadi semakin sukar melalui alat pengurusan pangkalan data konvensional. Di sinilah HBase datang ke gambar. HBase adalah pilihan pilihan untuk mengendalikan sejumlah besar data. Contohnya, jika anda perlu menapis melalui e -mel yang besar untuk mengeluarkan satu untuk pengauditan atau untuk tujuan lain, ini akan menjadi kes penggunaan yang sempurna untuk HBase. Hive, sebaliknya, lebih seperti sistem pelaporan gudang data tradisional yang berjalan di atas Hadoop. Hive menawarkan bahasa pertanyaan seperti SQL yang membolehkan anda menanyakan data separa berstruktur yang disimpan di Hadoop. Ini memerlukan usaha yang tidak perlu untuk menulis kod MapReduce. Walaupun, kedua -dua HBase dan Hive digunakan sebagai kedai data untuk menyimpan data yang tidak berstruktur, mereka berbeza.
Apa itu HBase?
HBase adalah sistem pengurusan pangkalan data terbuka, bukan hubungan, pangkalan data yang diilhamkan oleh seni bina meja besar Google dan ditulis di Java. HBase pada asasnya adalah pangkalan data NoSQL yang berorientasikan lajur yang diedarkan di atas sistem fail yang diedarkan Hadoop (HDFS). Ia direka dan dibangunkan oleh banyak jurutera di bawah rangka Yayasan Perisian Apache. Ia terletak di Apache Hadoop dan dikuasakan oleh struktur fail yang diedarkan dengan toleransi yang dikenali sebagai HDFS. Ia menyediakan cara untuk menyimpan set data jarang, yang biasa dalam kes penggunaan data besar. Ia membolehkan membaca data akses rawak cepat dari sejumlah besar data berdasarkan nilai utama. Walau bagaimanapun, ia tidak direka untuk melakukan agregasi data.
Apa itu sarang?
Hive bukanlah pangkalan data tetapi pakej pergudangan data yang dibina di atas Hadoop. Hive adalah teknologi yang berbeza daripada HBase; Ia menyusun data dalam satu set jadual yang boleh disatukan, diagregatkan dan ditanyakan apabila menggunakan bahasa pertanyaan yang dipanggil Hive Query Language (HQL) yang sangat mirip dengan SQL, yang digunakan untuk pemprosesan batch data besar. Ia membolehkan anda untuk menanyakan data separa berstruktur yang disimpan di Hadoop, yang akhirnya menjadi pekerjaan MapReduce, dilaksanakan sama ada secara tempatan atau di kluster MapReduce yang diedarkan. Hive pada dasarnya adalah sistem gudang data untuk Hadoop yang memudahkan ringkasan data mudah, pertanyaan ad-hoc, dan analisis set data besar yang disimpan dalam sistem fail serasi Hadoop. Data boleh dibaca dan ditulis dari Hive dan HBase dan sebaliknya. Walau bagaimanapun, ia tidak boleh digunakan untuk pemprosesan masa sebenar data.
Perbezaan antara HBase dan Hive
Teknologi
- Walaupun HBase dan Hive adalah kedua -dua struktur gudang data berasaskan Hadoop yang digunakan untuk menyimpan dan memproses sejumlah besar data, mereka berbeza dengan ketara tentang bagaimana mereka menyimpan dan menanyakan data. HBase pada asasnya merupakan pangkalan data NoSQL yang berorientasikan lajur yang diedarkan di atas sistem fail yang diedarkan Hadoop (HDFS) dan menyediakan cara yang tidak puas hati untuk menyimpan set data yang jarang, yang biasa digunakan dalam kes data besar. Hive, sebaliknya, tidak betul -betul pangkalan data tetapi pakej pergudangan data yang dibina di atas Hadoop. Hive lebih seperti sistem pelaporan pergudangan data tradisional.
Seni bina
- HBase adalah pangkalan data NoSQL dan pelaksanaan sumber terbuka seni bina meja besar Google yang terletak di Apache Hadoop dan dikuasakan oleh struktur fail yang diedarkan dengan toleransi yang dikenali sebagai HDFS. Ini adalah penyelesaian penyimpanan berskala untuk menampung jumlah data yang hampir tidak berkesudahan. Ia adalah seni bina penyimpanan data yang digunakan untuk menyimpan data yang tidak berstruktur. Hive, sebaliknya, adalah enjin SQL yang dibina di atas HDFS dan memanfaatkan MapReduce secara dalaman, yang membolehkan pertanyaan data yang disimpan pada HDFS melalui bahasa pertanyaan seperti SQL yang dipanggil HQL (Hive Query Language).
Gunakan
- HBase digunakan untuk membina perkhidmatan lapisan rendah, fleksibel, dan mudah untuk mengekalkan perkhidmatan lapisan jubin - Sistem Maklumat Geografi Berdasarkan Hadoop (HBGIS) - agar penyimpanan data besar -besaran. Ini adalah format penyimpanan lajur on-cakera yang menyediakan cara untuk menyimpan set data yang jarang, yang biasa dalam kes penggunaan data besar. Ia membolehkan membaca data akses rawak cepat dari sejumlah besar data berdasarkan nilai utama. Hive, sebaliknya, adalah standard untuk pertanyaan SQL atas petabytes data di Hadoop dan menyediakan bahasa pertanyaan seperti SQL yang dipanggil HQL untuk menanyakan data yang disimpan dalam cluster Hadoop.
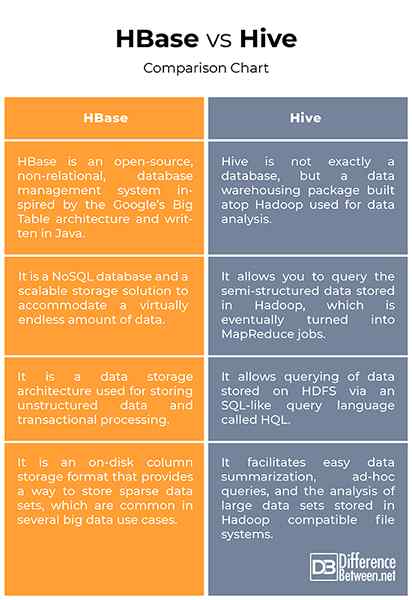
HBase vs. Hive: Carta Perbandingan
Ringkasan
Walaupun HBase dan Hive adalah kedua -dua struktur gudang data berasaskan Hadoop yang digunakan untuk menyimpan dan memproses sejumlah besar data, mereka berbeza dengan ketara tentang bagaimana mereka menyimpan dan menanyakan data. HBase adalah sistem pengurusan pangkalan data berorientasikan lajur yang digunakan untuk penyimpanan data besar-besaran dan menyediakan cara untuk menyimpan set data yang jarang, yang biasa dalam beberapa kes penggunaan data besar. Hive, sebaliknya, lebih seperti sistem pelaporan gudang data tradisional yang dibina di atas Hadoop yang digunakan untuk menjalankan pemprosesan melalui pekerjaan jadual dan kemudian memuatkan hasilnya ke dalam jadual jenis ringkasan yang dapat dipertimbangkan lagi oleh aplikasi klien.
- « Perbezaan antara pemasaran pemasaran dan pemasaran kandungan
- Perbezaan antara Hadoop dan Mongodb »