

Perbezaan antara Hadoop dan Mongodb
- 3010
- 343
- Mrs. Ted Marks
Kami telah mendengar istilah data besar untuk beberapa waktu sekarang, tetapi apa sebenarnya data besar ini? Jumlah data yang dihasilkan oleh Internet Things telah meningkat secara dramatik selama bertahun -tahun dan ia terus meningkat pada kadar eksponen. Pemprosesan jumlah data besar -besaran ini tidak sesuai untuk kaedah tradisional untuk mengendalikan disebut sebagai data besar. Data seperti ini menimbulkan cabaran kepada sistem RDBMS tradisional yang digunakan untuk menyimpan dan memproses data. Kuasa pemprosesan yang diperlukan untuk menyimpan dan memproses banyak data ini tepat pada masanya dan kos efektif adalah besar -besaran. Untuk menangani masalah ini, penyelesaian data besar yang baru dan bertambah baik diperlukan yang direka khusus untuk memproses data tidak berstruktur yang besar. Dari banyak teknologi, Hadoop dan MongoDB adalah dua pilihan yang popular ketika menyimpan dan memproses data besar. Walaupun kedua -duanya agak serupa pada dasarnya apa yang mereka lakukan, tetapi pendekatan mereka terhadap bagaimana mereka melakukannya agak berbeza. Mari lihat.
Apa itu MongoDB?
MongoDB adalah pangkalan data dokumen sumber terbuka yang telah berkembang menjadi pangkalan data de facto noSQL dengan berjuta-juta pengguna, dari permulaan kecil hingga 500 syarikat. Syarikat terkemuka dan syarikat IT pengguna memanfaatkan keupayaan MongoDB dalam produk dan penyelesaian mereka. Ditulis dalam C ++, MongoDB adalah pangkalan data berorientasikan platform, dokumen yang berkesan menangani batasan pangkalan data berasaskan skema SQL dengan menyediakan prestasi tinggi, ketersediaan tinggi, dan penyelesaian skalabiliti yang mudah. Ia adalah pangkalan data yang direka untuk web moden. Seperti pangkalan data NoSQL yang lain, MongoDB tidak mematuhi prinsip RDBMS tanpa konsep jadual, baris dan lajur. Ia menyimpan datanya dalam dokumen BSON di mana semua data yang berkaitan diletakkan bersama dalam satu dokumen.
Apa itu Hadoop?
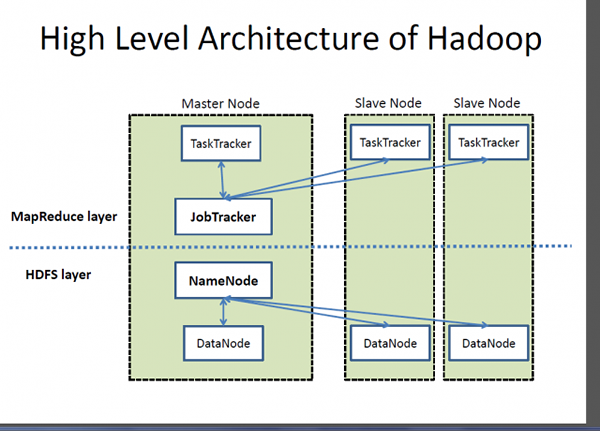
Hadoop adalah rangka kerja sumber terbuka yang direka untuk penyimpanan dan memproses jumlah data yang besar di seluruh kelompok komputer. Ia adalah aplikasi berdasarkan Java dan koleksi perisian yang berbeza yang menghasilkan rangka kerja pemprosesan data. Ideanya adalah untuk memproses data berskala besar dengan kos yang berpatutan dalam masa yang paling mungkin. Hadoop terdiri daripada tiga sumber utama: sistem fail yang diedarkan Hadoop (HDFS), platform pengaturcaraan MapReduce Google, dan keseluruhan ekosistem Hadoop. Ekosistem Hadoop terdiri daripada modul yang membantu memprogram sistem, mengurus dan mengkonfigurasi kluster, mengurus dan menyimpan data dalam kluster dan melaksanakan tugas analitik. Hadoop MapReduce AIDS Data Analytics memproses sejumlah besar data berstruktur dan tidak berstruktur. Hadoop adalah tanda dagangan berdaftar dari Apache Software Foundaton dan MapReduce adalah kerangka kerja untuk pemprosesan selari.
Perbezaan antara Hadoop dan Mongodb
Platform
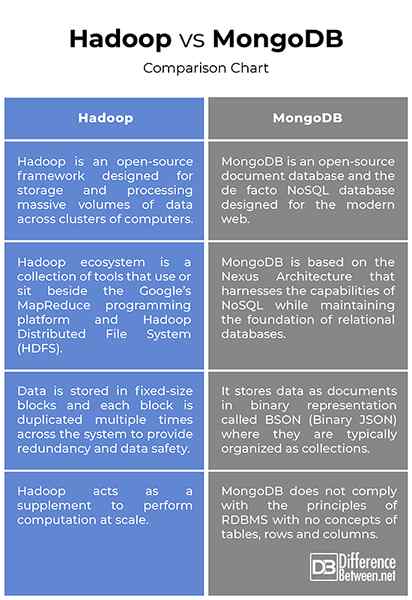
- Walaupun kedua-duanya dianggap sebagai penyelesaian data besar, MongoDB pada dasarnya merupakan platform tujuan umum yang direka untuk menggantikan atau memperbaiki sistem RDBMS yang ada. MongoDB adalah pangkalan data dokumen sumber terbuka dan salah satu pangkalan data NoSQL terkemuka yang menggunakan dokumen, bukan baris dan jadual, untuk menjadikannya fleksibel, berskala, dan cepat. Hadoop, sebaliknya, adalah rangka kerja sumber terbuka yang direka untuk penyimpanan dan memproses jumlah data yang besar di seluruh kelompok komputer. Hadoop tidak dimaksudkan untuk menggantikan sistem RDBMS yang sedia ada; Malah, ia bertindak sebagai suplemen untuk membantu analisis data memproses jumlah besar data berstruktur dan tidak berstruktur.
Seni bina
- Ekosistem Hadoop adalah koleksi alat yang menggunakan atau duduk di sebelah platform pengaturcaraan MapReduce Google dan HDFS (Hadoop diedarkan sistem fail) untuk menyimpan dan menganjurkan data, dan menguruskan mesin yang menjalankan Hadoop. HDFS direka untuk mengakses data streaming. Sebaliknya, MongoDB menawarkan pendekatan yang berbeza; Ia berdasarkan seni bina Nexus yang memanfaatkan keupayaan NoSQL sambil mengekalkan asas pangkalan data relasi. Ia menyimpan data sebagai dokumen dalam perwakilan binari yang dipanggil BSON (Binary Json) di mana mereka biasanya dianjurkan sebagai koleksi.
Kekuatan
- Kekuatan terbesar Hadoop adalah MapReduce. Hari ini Hadoop adalah kerangka MapReduce terbaik di pasaran. Konsep di sebalik MapReduce ialah input boleh dibahagikan kepada ketulan logik, di mana setiap bahagian boleh diproses secara bebas oleh tugas peta. Tugas peta boleh dijalankan di mana -mana nod pengiraan dalam kelompok dan pelbagai tugas peta dapat berjalan selari di seluruh kluster. MongoDB, sebaliknya, adalah pangkalan data dokumen yang dapat mengendalikan beban mulai dari MVPS dan POC permulaan untuk aplikasi perusahaan dengan beratus -ratus pelayan. MongoDB telah berkembang dari menjadi penyelesaian pangkalan data khusus ke pangkalan data de facto noSQL. Pengertian dokumennya benar -benar ekspresif dan fleksibel.
Hadoop vs. MongoDB: Carta Perbandingan
Ringkasan
Walaupun kedua -duanya agak serupa pada dasarnya apa yang mereka lakukan, tetapi pendekatan mereka terhadap bagaimana mereka melakukannya agak berbeza. MongoDB menyimpan data sebagai dokumen dalam perwakilan binari yang dipanggil BSON, sedangkan di Hadoop, data disimpan dalam blok saiz tetap dan setiap blok ditiru beberapa kali di seluruh sistem. Ekosistem Hadoop adalah koleksi alat yang menggunakan atau duduk di sebelah platform pengaturcaraan MapReduce Google, sedangkan MongoDB berdasarkan seni bina Nexus yang memanfaatkan keupayaan NoSQL sambil mengekalkan asas pangkalan data hubungan.