

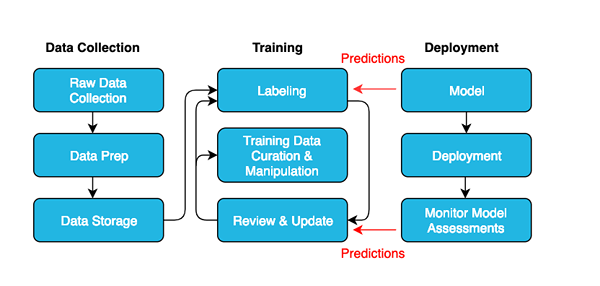
Perbezaan antara anotasi data dan pelabelan
- 1534
- 114
- Ricardo Koelpin IV
Selama bertahun -tahun, syarikat telah melabur dalam pembelajaran mesin. Malah, pembelajaran mesin adalah salah satu bidang penyelidikan yang paling aktif dalam bidang kecerdasan buatan (AI). Matlamat utama penyelidikan dalam bidang pembelajaran mesin adalah untuk mewujudkan mesin atau komputer yang cerdas, sedar diri yang mampu mereplikasi kemahiran kognitif manusia dan memperoleh pengetahuan sendiri. Oleh itu, memahami pembelajaran manusia dengan cukup baik untuk menghasilkan semula aspek tingkah laku pembelajaran dalam mesin adalah saintifik yang layak dalam dirinya sendiri. Setiap hari manusia mengajar komputer untuk menyelesaikan banyak masalah baru dan menarik, seperti memainkan senarai main kegemaran anda, menunjukkan arah memandu ke restoran terdekat anda, dan sebagainya.
Tetapi masih terdapat banyak perkara yang tidak dapat dilakukan oleh komputer, terutamanya dalam konteks memahami tingkah laku manusia. Kaedah statistik telah terbukti menjadi cara yang berkesan untuk mendekati masalah ini, tetapi teknik pembelajaran mesin berfungsi dengan lebih baik apabila algoritma disediakan dengan petunjuk kepada apa yang relevan dan bermakna dalam dataset, dan bukannya besar data. Dalam konteks pemprosesan bahasa semulajadi, petunjuk ini sering datang dalam bentuk anotasi - seni pelabelan data yang terdapat dalam format yang berbeza. Anotasi dan pelabelan data adalah dua elemen asas pembelajaran mesin yang membantu mesin mengenali imej, teks dan video.
Apakah anotasi data?
Cukup menyediakan komputer dengan sejumlah besar data dan mengharapkannya untuk belajar bercakap tidak mencukupi. Data harus dikumpulkan dan dibentangkan sedemikian rupa sehingga komputer dapat dengan mudah mengenali corak dan kesimpulan dari data. Ini biasanya dilakukan dengan menambahkan metadata yang relevan kepada satu set data. Sebarang tag metadata yang digunakan untuk menandakan unsur -unsur dataset dipanggil anotasi atas input. Oleh itu, dalam pembelajaran mesin, data mesti dijelaskan, atau hanya mengatakan, dilabelkan, supaya sistem dapat mengenalinya dengan mudah. Tetapi, bagi algoritma untuk belajar dengan berkesan dan cekap, anotasi pada data mestilah tepat dan relevan dengan pekerjaan yang ditugaskan oleh komputer. Ringkasnya, anotasi data adalah teknik pelabelan data supaya mesin dapat memahami dan menghafal data input.
Apakah pelabelan data?
Data datang dalam pelbagai bentuk seperti teks, imej, audio, dan video. Untuk memperkayakan data supaya mesin dapat mengenalinya melalui algoritma pembelajaran mesin, data perlu dilabelkan. Pelabelan data, seperti namanya, adalah proses mengenal pasti data mentah supaya melampirkan makna kepada pelbagai jenis data untuk melatih model pembelajaran mesin. Apabila data dilabelkan, ia digunakan untuk latihan algoritma lanjutan untuk mengenali corak pada masa akan datang. Pelabelan pada dasarnya menandakan data atau menambah metadata untuk menjadikannya lebih bermakna dan bermaklumat supaya mesin dapat memahaminya dan belajar daripadanya. Sebagai contoh, label mungkin menunjukkan bahawa imej mengandungi seseorang atau haiwan, atau fail audio di mana bahasa, atau untuk menentukan jenis tindakan yang dilakukan dalam video.
Perbezaan antara anotasi data dan pelabelan
Makna
- Kedua -dua pelabelan data dan anotasi adalah istilah yang sering digunakan secara bergantian untuk mewakili proses penandaan atau pelabelan data yang terdapat dalam banyak format yang berbeza. Anotasi data pada dasarnya adalah teknik pelabelan data supaya mesin dapat memahami dan menghafal data input menggunakan algoritma pembelajaran mesin. Pelabelan data, juga dipanggil penandaan data, bermaksud melampirkan makna kepada pelbagai jenis data untuk melatih model pembelajaran mesin. Pelabelan mengenal pasti entiti tunggal dari satu set data.
Tujuan
- Pelabelan adalah landasan pembelajaran mesin yang diawasi dan pelbagai industri masih sangat bergantung pada anotasi dan pelabelan data mereka secara manual. Label ini digunakan untuk mengenal pasti ciri dataset untuk algoritma NLP manakala anotasi data boleh digunakan untuk model persepsi berasaskan visual. Pelabelan lebih rumit daripada penjelasan. Anotasi membantu mengenali data yang relevan melalui penglihatan komputer manakala pelabelan digunakan untuk latihan algoritma lanjutan untuk mengenali corak pada masa akan datang. Kedua -dua proses perlu dilakukan dengan ketepatan mutlak untuk memastikan sesuatu yang bermakna keluar dari data supaya membangunkan model AI berasaskan NLP.
Aplikasi
- Anotasi data adalah elemen asas dalam mewujudkan data latihan untuk penglihatan komputer. Data anotasi diperlukan untuk melatih algoritma pembelajaran mesin untuk melihat dunia ketika kita manusia melihatnya. Idea ini adalah untuk menjadikan mesin cukup pintar untuk belajar, bertindak dan berkelakuan seperti manusia, tetapi dari mana kecerdasan ini berasal? Jawapannya adalah data dan banyak dan banyaknya. Anotasi adalah proses yang digunakan dalam pembelajaran mesin yang diawasi untuk set data latihan untuk membantu mesin memahami dan mengenali data input dan bertindak dengan sewajarnya. Pelabelan digunakan untuk mengenal pasti ciri -ciri utama yang terdapat dalam data sambil meminimumkan penglibatan manusia. Kes penggunaan dunia sebenar termasuk NLP, Audio dan Pemprosesan Video, Visi Komputer, dan lain -lain.
Anotasi data vs. Pelabelan data: carta perbandingan

Ringkasan
Anotasi adalah proses yang digunakan dalam pembelajaran mesin yang diawasi untuk set data latihan untuk membantu mesin memahami dan mengenali data input dan bertindak dengan sewajarnya. Pelabelan digunakan untuk mengenal pasti ciri -ciri utama yang terdapat dalam data sambil meminimumkan penglibatan manusia. Pelabelan adalah landasan pembelajaran mesin yang diawasi dan pelbagai industri masih sangat bergantung pada anotasi dan pelabelan data mereka secara manual. Kerana pelabelan yang lemah boleh menyebabkan AI yang dikompromi, pelabelan atau anotasi mesti dilakukan dengan tepat supaya mereka dapat digunakan untuk aplikasi AI.